一、前言
由於深度學習等機器學習技術在理論及實務上的進展,人工智慧已經成為資訊科技相關研究與應用的核心之一。人工智慧已經被廣泛的運用在許多領域,例如影像辨識、語音辨識、自動駕駛等,而在金融科技、生物醫學等領域也正快速發展中。人工智慧的發展可追溯至 1950 年代,但直至近期由於電腦運算能力、大量資料與儲存容量的增加,以及機器學習演算法的改進,獲得許多突破性的進展,因而重新成為資訊科技研究與應用的焦點。人工智慧賦予電腦自我學習的能力,使電腦得以藉由大量的資料自我訓練,跳脫僅能單純執行指令的限制。人工智慧可以協助使用者從過往的數據中預測未來,也可以將諸多工作自動化,足以改變未來社會的形貌。
人工智慧創新應用專題中心 (Artificial Intelligence Innovation Center) 整合資創中心研究資源,並對外做為橋接產業的窗口,促進產業提升及學術、技術交流。本專題中心研究方向將專注於人工智慧相關技術應用與服務之研究,除持續投注資源於人工智慧技術的研究與應用之外,並將積極與國內外單位合作、培育國內外人才,與其他學門及產業合作跨領域研究,務求在人工智慧的議題上除了技術進展外,亦能探討其對未來社會、經濟以及產業發展上的影響。
二、研究方向及成果
多媒體相關研究
目前人工智慧在多媒體應用上,許多演算法已經具有超越人類的表現,但仍存有相當多挑戰的議題。本中心在電腦視覺應用方面,有許多重要研究成果,包括善用不同視覺型態的特性來降低標註資料的成本,以及達成深度模型的調適,以適用於影像語義分割。在人臉辨識部分,該技術雖然已經在各種認證場景中被廣泛採用,但仍包含許多安全性和公平性的研究議題有待深入研究。在音樂領域方面,包括自動音樂生成,可以生成無版權音樂並應用於廣告配樂、電影配樂、遊戲音樂等。以下是本中心在多媒體領域的研究方向與成果:
‧ 電腦視覺
隨著訊號感測器科技進步,不少有別於影像的視覺資料型態開始受到重視,我們的研究方向具體包括以下四個資料型態及相關應用:1) 影片去模糊:在模糊測試影片中,不同幀 (frame) 因物體移動有不盡相同的模糊程度,但卻有相似的特性,透過估測去模糊效果較好的幀,作為調適模型而用,可以達到更高的效能;2) 360°影像超解析:利用 360°影像在某些特定投影方式可遞迴性,以及自相似性來動態提高 360°影像超解析的效能;3) 點雲語意分割:開發點雲協同分割 (co-segmentation) 的演算法,讓模型在無監督的狀況下學習點雲語意分割;4)影片聲音定位:利用多模態資料的特性,進行跨資料間的影片及聲音的配對,據此進行資料擴增,以利進行自監督和對比式學習,讓模型在弱監督式的標註情況下有更高的效能。現有的影像語義分割 (semantic segmentation) 方法僅適用於訓練資料有包含的物件類別, 這限制了學習後的分割模型的適用性。為了突破此一限制,研究團隊開發了一個新的網路模型,稱為可傳移層 (transferable layer),它可將知識從訓練料所包含的物件類別轉移到任意類別,並據此切割訓練資料所未包含之物件類別。具體來說,我們假設未知的物件類別的 activation map 是訓練資料所包含類別之activation maps 的線性組合,並利用包含視訊中的物體連續位移資訊來預測線性組合之係數。因此無論訓練影像中是否包含測試影像的物件類別,此方法所訓練出的模型都可以對物件進行分割。本項研究及其延伸成果發表於 ACCV 頂尖會議以及頂尖期刊 IJCV 2020,同時前者也獲得之最佳學生論文獎榮譽提名。
在人臉辨識部份,我們致力於人臉反欺騙及偽造人臉偵測、視覺隱私、及電腦視覺模型之對抗樣本攻擊與防禦,其中包括1) 人臉反欺騙及偽造人臉偵測及2) 電腦視覺模型之對抗樣本攻擊與防禦相關研究, 預期能對於近來氾濫的假消息和機器學習模型的安全漏洞進行補強。此部分對於基於深度學習技術之電 腦視覺模型訓練,仰賴大量的影像標註資料,但標註資料需要大量人工標註還有標籤除錯,更遑論標註 資料量更大的影片資料,因此,在此方面我們有許多成果,例如開發基於自監督學習之物體追蹤演算法, 透過對物體進行不同轉換產生訓練資料以及對比學習,有效訓練物體追蹤器。對於車輛重識別任務,如 何學習到一個可分辨的特徵是最迫切需要解決的問題,但因為許多車的外觀都非常相似,尤其是同一種 車款,為了解決這個問題,我們與美國馬里蘭大學合作夥伴設計了基於自監督學習之注意力引導特徵學 習演算法,該演算法能偵測到許多細微的外觀差異,引導模型學習到適合的特徵進行後續比對。以上研 究成果發表於多媒體頂尖會議 ACM MM。未來將會加強各種電腦視覺模型之於對抗樣本或偽造人臉攻擊的完備性,或是解決模型偏見的問題,如大部分人臉資料集以西方白人的居多,造成實際系統運行時, 其他不同膚色種族的辨識率較差。
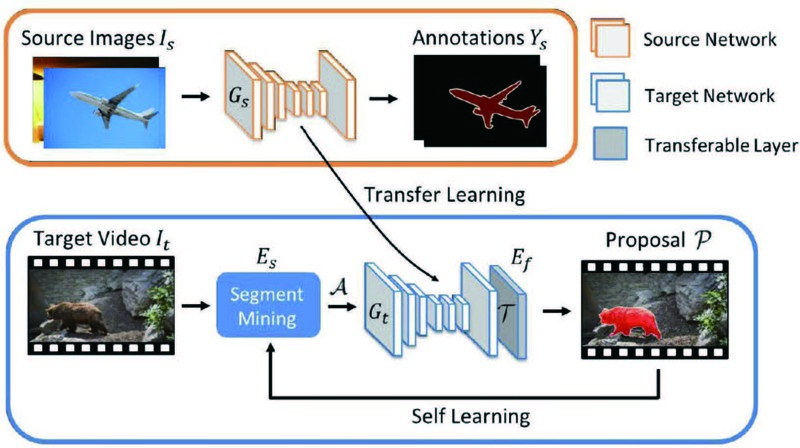
圖 1、運用可轉移層方法的網路架構圖
‧ 自動音樂生成
自動作曲可以分作有條件或是無條件的:在前者,人們須提供 AI 一部分的輸入,例如弦律、和 弦、歌詞、或是音樂片段,而由 AI 完成完整歌曲。在後者,AI 需要從頭到尾自己憑空發想並完成音樂創作。本中心團隊兩者皆有所研究,並且所開發的模型不只能產生樂譜,也能學習如何演奏該樂譜。本 中心的團隊已經在自動作曲的研究上有許多指標性的成就,於 2017 年與 2018 年分別開發出 MidiNet 與 MuseGAN,分別為國際上第一個將捲積式對抗生成網路應用於單軌及多軌音樂生成的模型。自2019 年起, 開始研究用自然語言生成當中近來常用的 Transformer「自注意力機制」來實現全自動音樂生成。除了發現自注意力機制可以讓 AI 產生具有長時間架構的音樂之外,也發現文獻上現有模型對於產生流行音樂的不足之處,並提出兩個改進版的模型。其一為一個新的命名為 Pop Music Transformer 的新架構,使的 AI模型學會「數拍」,進而大為提升了生成音樂的節奏感;透過實驗證實該新模型所產生的流行鋼琴音樂 比Google 團隊在 2019 年所提出的一個模型更為好聽。其二為一個名為 Compound Word Transformer 模型, 讓 Transformer 的訓練和產生音樂時間都大幅縮短;該模型也同時是世界上第一個能夠直接生成全曲長度音樂的 AI 模型。以上成果多次發表於國際頂尖會議 AAAI、IJCAI、和 ACM MM。透過與國內 AI 研究單位臺灣人工智慧實驗室 (Taiwan AI Labs) 合作,接下來將專注之研究題目將包含生成更具多樣性、且具結構性之音樂,並探討 AI 音樂如何與人類互動。
醫療相關研究
在基於人工智慧之醫療方面,本中心投入口語溝通輔具開發,協助生活上有障礙的人,致力於開發基於 AI 以及先進訊號處理技術為基礎的聽覺輔具科技,目標是改進現有的聽覺輔具,幫助聽障人士提升聽覺效能。此外,亦研究開發醫療方面之影像辨識和處理分析模型,輔助臨床醫師診斷。
‧ 聽覺醫療輔具
我們基於深度學習理論,提出語音訊號處理演算法於除噪、除混響、以及通道補償等議題,這些議題的共通目標在於增進聲音的品質,提昇人與人、人與機器之間的溝通效率。我們特別研發對理解力以及語音品質強化的演算法,以實現優良的語音辨識率及良好的口語溝通品質。此外,我們提出端對端語音波形增強法,以提高前述的語音理解度及聲音品質。同時,亦提出整合深度及總體學習演算法及環境調適演算法,減輕在真實應用情境上可能遭遇到的訓練、測試環境不匹配問題。另一個重要的研究主題是結合多模態之語音訊號處理技術,主要是結合視覺、震動與聲音訊號的方法,以提高語音訊號處理的效能。目前,我們提出了能有效提升效能的演算法,應用於情緒辨識、口語演講評分及語音增強,未來將應用於口語溝通輔具開發。以上研究成果已多次發表在相關領域頂級期刊,相關臨床實驗結果也獲得數篇國內外專利,並且持續與榮民總醫院、振興醫院、啟聰學校進行合作研究,也已多次發表在相關領域頂級期刊。這些研究成果技轉至工業界,並於 2018、2019、2020 年度獲得國家新創獎、2019 年美律電聲論文獎金質獎、中華扶輪教育基金會 2019-2020 年度傑出人才獎。我們期待研究成果真正地對國內口語溝通障礙族群帶來幫助,進而能夠讓台灣在發展語音及生醫訊號處理的研究上佔有前瞻性地位。
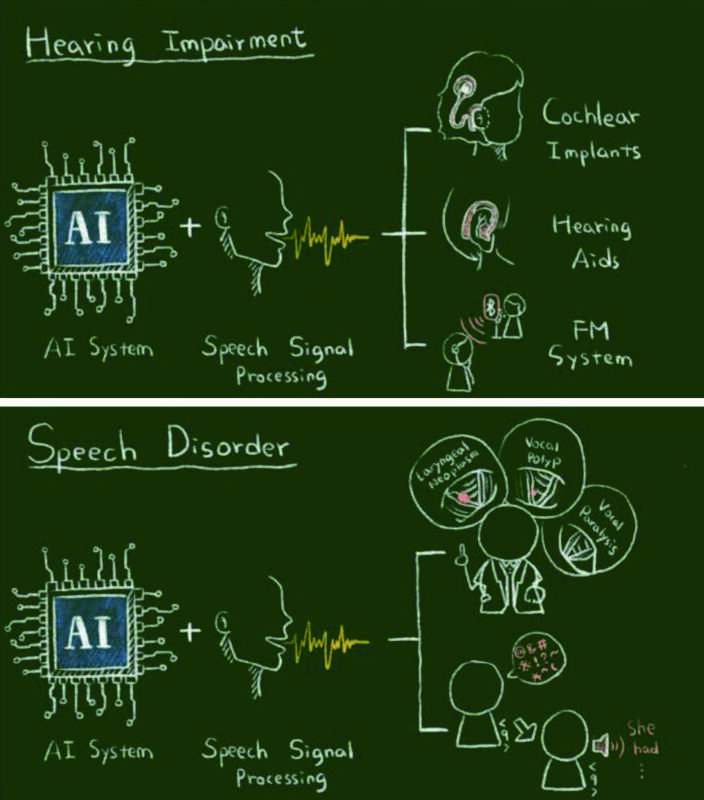
圖 2、基於 AI 的聽覺(調頻輔具、助聽器和人工耳蝸)與口語輔具技術
‧ 醫療影像分析
肝腫瘤研究目的為辨識電腦斷層掃描圖中的異常肝組織的辨識,以轉移學習 (Transfer Learning) 技術建構出之辨識系統,達到相較於醫檢師標記更精準的異常組織識別。針對醫療影像 AI 應用深化研究機器學習與深度學習技術,並與醫師合作,根據 1) 病理切片證實,2) 典型的影像學特徵在肝癌的診斷上,尋求癌細胞影像判讀因素,以辨識能力指標,配置辨識決策變數,目的在以錯誤率最小化為目標函數,透過機器學習找出最佳辨識策略,提升以影像來確診肝腫瘤的正確率。目前研究成果,肝腫瘤辨識正確率為 70%。另外,以台大醫院既有之腎臟醫療影像資料集,電腦斷層掃描 (Computed Tomography, CT) 或核磁共振成像 (Nuclear Magnetic Resonance Imaging, MRI),針對多囊腎臟病 (Autosomal Dominant Polycystic Kidney Disease, ADPKD),俗稱泡泡腎,的病患影像資料,透過設計深度學習的演算法,以精準辨認腎臟位置為目標,再將其堆疊成腎組織體積,進行患者的腎臟區域辨識與偵測,進而精準計算出該患者腎臟體積。藉由此深度學習模型的建立,希冀解決人員判定費時的問題,及精準計算出泡泡腎患者腎體積的大小,研究成果目前腎組織辨識正確率為 97%,並持續精進中。
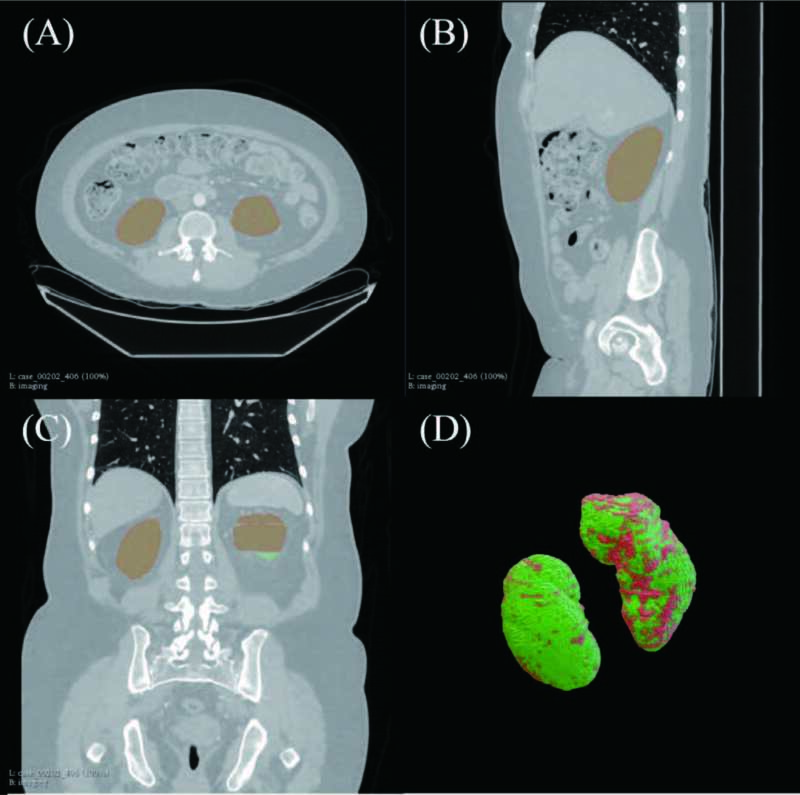
圖 3、運用 ResNet-50 and Unet 結構進行腎臟區域辨識。(A) 橫切面 (B) 矢狀切面 (C) 額狀切面 (D) 3D 腎臟切片堆疊;紅色區域表示預測結果,綠色區域表示原始標記區域。
金融相關研究
人工智慧在金融領域的相關研究可幫助我國既有產業升級,並開創新的商業模式或是使用者體驗。本中心團隊投入研究計算、智能、財務和語言學四個領域共同交集或聯集之問題。此外,亦致力於開發視覺化和互動式資訊系統與應用模型原型,此舉不僅可用於檢查所提出方法之實用性,並可促進跨領域研究之進程。研究主要如下。在財務計算部分之研究,包括衍生產品定價,樹狀模型,資本結構和模擬方法。在該領域的所有研究中,主要專注於開發有效且準確的數值方法 ( 例如:樹狀模型模型和蒙地卡羅模擬演算法 ),用以進行複雜之衍生性金融商品及債券的定價。在財務資料分析方面,近年來致力於利用機器學習演算法於金融非結構化和具時序資料之建模。對於非結構化資料,我們進行了一系列基於財務報告中文字資訊進行之風險分析及預測的研究。關於財務時間序列之相關研究,主要研究與企業信用分析有關的研究問題。另一方面,我們亦致力於開發有效的圖形表示式學習演算法和深度神經模型,主要用於推薦及或資訊檢索的相關應用;而多項開發的方法亦在許多產學合作中廣泛的使用。 這些研究多次發表於頂級期刊和國際會議上,並獲得最佳論文獎,此外也透過與產業界合作,如中華民國證券櫃檯買賣中心、國泰金控、KKStream 及玉山銀行,建立現實解決方案。未來將把更多的研究重心放在針對具有時序性之資料的建模並找尋或開發有趣且關鍵的跨學科之應用。不論在在金融,醫學,工程學和氣候科學等領域中,這一類型的資料是十分常見且重要的,它們自然地存在於涉及股票預測、視覺分析以及天氣預報等應用。然而與靜態資料相比,具時間性質的資料本質上要復雜得多,因為它們時常伴隨大量雜訊,具有高維度的資料特性,且在許多情況下是不穩定的序列。這些特性大幅限制了大多數標準統計模型和深度學習方法,因此對此類型之資料進行建模是一個十分具有挑戰且重要的研究議題。
強化學習相關研究
近年來,在人工智慧領域的許多應用問題中,結合深度學習與強化學習的方法 (Deep Reinforcement Learning; DRL),都獲得突破性的成果。其一就是DeepMind 發展的 AlphaGo 圍棋程式大幅超越職業棋士; 而後更進一步發展 AlphaZero 技術,從「零知識」開始學圍棋,無須專家棋士資訊,即可超越所有人類棋士,這自我學習的能力,對未來人工智慧的發展,將有很深遠的影響與衝擊。在此部分,本中心團隊研究探索各種強化學習的應用問題。
我們將深度強化學習之應用分為如下三類:第一、簡易環境應用問題如對局遊戲,這類問題可利用AlphaZero 與蒙地卡羅樹搜尋 (MCTS) 演算法,在不使用人類知識下達到或甚至超越專家級水準。在此部份,本中心團隊也獲得許多突破性的研究成果。首先,我們提出一套新方法,運用 PBT (population based training) 方法來動態調整 AlphaZero 超參數,以此大幅改良所研發的圍棋程式,並實證此方法可以大幅提升勝率,優於 Facebook 團隊所研發之 ELF OpenGo 程式,並可以省下至少十倍以上運算資源,此方法未來也可運用於其他應用問題。我們也提出一套新的強度( 如棋力) 調整演算法,適用於MCTS 為主的程式; 由於 MCTS 有高的泛化性,此技術也可泛化到許多其他遊戲,如西洋棋、日本將棋,甚至可延伸到其他非棋類問題上。我們以此為基礎發展出一套能提供圍棋棋力的系統,為世界第一個能涵蓋初學 18 級到超越職業九段的系統,同時也可以在對弈過程中動態偵測棋手棋力。以上成果均發表論文於國際頂尖會議與期刊,同時也獲得多項科技部獎項,也被用於培訓圍棋國家隊等級的職業棋士。第二、複雜環境應用問題,如電玩遊戲、智慧交通控制、甚至延伸至網路通訊問題,這類問題可運用以價值為基礎、以策略為基礎的強化學習方法來學習。在網路通訊方面,將針對以下兩個問題設計出最佳的強化學習演算法。a) 下世代無線通訊將使用大型多天線系統下的檢測;b)下世代無線通訊之最佳分配網路負載,並探討其中的權衡議題。第三、實體環境應用問題,如自駕模型賽車、機器手臂、無人機,這類問題可運用模仿學習、 轉移學習、元學習等方法。我們研究探索如何運用一些強化學習方法如近端策略最佳化(PPO) 和深度策略梯度 (Deep Policy Gradient),實現模型賽車系統,目前在國際競賽中多次獲得前三名的佳績。
三、未來展望
基於過去研究成果繼續在上述研究領域鑽研關鍵技術,以獲得更多更具影響力的成果。例如:在電腦視覺方面的研究,包括影片去模糊、360 影像超解析、點雲語意分割、影片聲音定位;在人臉辨識方面, 繼續探索人工智慧模型安全、隱私、和公平性的相關研究課題;在音樂合成方面,研究如何生成更具多樣性、且具結構性之音樂,並探討 AI 音樂如何與人類互動;在醫學方面,讓研究成果能真正地幫助國內口語溝通障礙族群,以及以音訊處理分析肺音,有效對於臨床肺疾病患更即時的診斷;在金融方面,研究具有時序性之資料的建模;在強化學習方面,研究建立AlphaZero/MuZero 平台,以適用於更多應用問題。
對於這些研究規劃,我們有以下展望: 1) 持續在國際知名期刊以及研討會論文上發表研究成果,並在國際會議上給予重要演講,進而提升台灣在人工智慧領域的研究地位;2)與國內外頂尖大學、研究機構進行學術交流合作,擴大研究成果,以提昇國內人工智慧產業之競爭利基,例如在自動作曲方面,持續與國內 AI 研究單位臺灣人工智慧實驗室 (Taiwan AI Labs) 合作;3) 積極與產業合作,透過技轉或是開發 API 的方式將研究成果導入業界,例如在金融方面,將繼續開發多項視覺化和互動式資訊系統與應用模型原型,預計將廣泛使用於產學合作中;4)結合產學合作與跨領域研究,整合成實用性更高的成果, 以使社會能享受人工智慧帶來的益處,例如在醫療方面,將進行影像辨識和音訊處理分析的跨領域研究, 開發聽覺輔具科技,幫助聽障人士提升聽覺效能。